Task Deduplication
Here's the challenge with autonomous AI agents: they discover work independently. When you have multiple agents exploring different parts of a problem, they'll often realize the same thing needs to be done.
Agent A in Phase 3: "We need to optimize the database queries." Agent B also in Phase 3: "The database performance is slow, we should optimize the queries."
Same work. Different phrasing. Both agents create tasks.
Without deduplication, you'd waste resources having two agents do identical work.
How It Works
When an agent creates a task, Hephaestus converts the task description into a high-dimensional vector (an embedding) using OpenAI's text-embedding-3-large model. This captures the semantic meaning of what the task is asking for.
Then we compare this new task against all existing tasks within the same phase using cosine similarity:
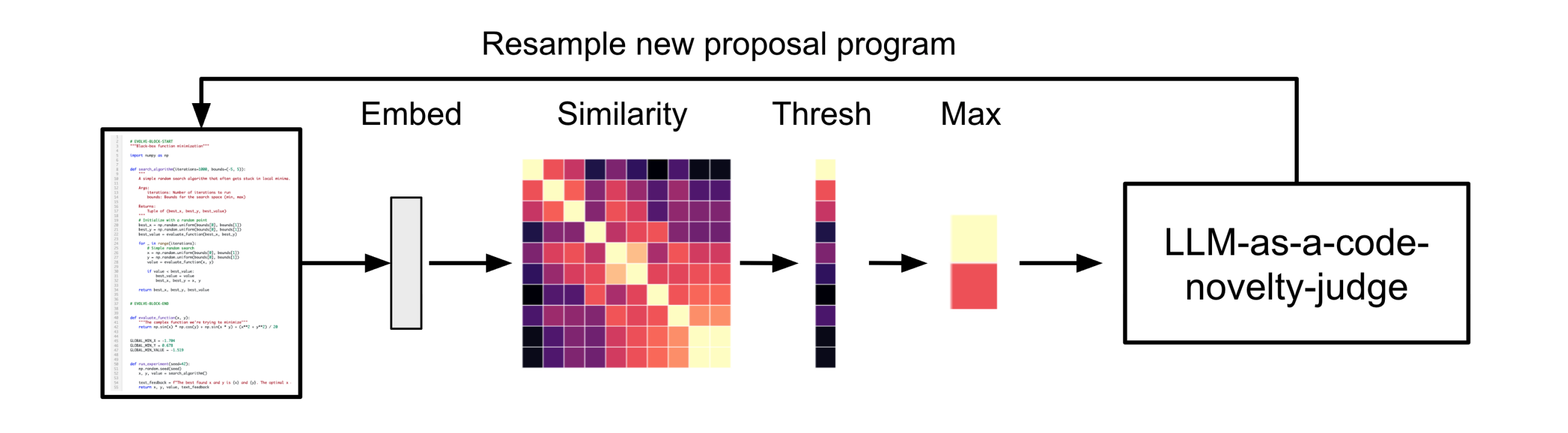 Figure: Cosine similarity measures how semantically similar two tasks are. Image from ShinkaEvolve, Section 3.2
Figure: Cosine similarity measures how semantically similar two tasks are. Image from ShinkaEvolve, Section 3.2
If the similarity exceeds the threshold (default: 0.92), the new task is marked as a duplicate. No agent is created. Resources saved.
Why This Matters
Hephaestus is deliberately unstructured. Agents aren't following a rigid script — they're discovering what needs to be done as they work. This creates immense flexibility but introduces a coordination problem.
Consider a multi-agent workflow:
Phase 2 Agent #3 is implementing an authentication feature. It discovers the admin module and thinks: "Someone should investigate how the admin API endpoints work."
Phase 2 Agent #7 is implementing file management. It successfully creates the upload feature and thinks: "Someone should check if this integrates properly with admin functionality."
Both agents want to investigate the admin module. Both create similar tasks.
Without semantic deduplication, you'd have two agents doing the same investigation. Cosine similarity catches this: the tasks are semantically similar even though the wording differs.
This approach is inspired by the ShinkaEvolve paper (Section 3.2), which demonstrates how program synthesis systems use semantic similarity to identify and reuse program blocks, preventing redundant computation.
Phase-Scoped Deduplication
Critical detail: Duplicate detection only happens within the same phase.
Why? Because different phases have different purposes. These tasks might look identical:
- Phase 1: "Analyze the authentication system" (reconnaissance)
- Phase 2: "Analyze the authentication system" (implementation)
- Phase 3: "Analyze the authentication system" (security audit)
They're semantically similar, but they serve different roles in different workflow stages. Phase 1 is discovering what exists. Phase 2 is building or modifying it. Phase 3 is validating it works.
The rule: Tasks are only compared to other tasks in the same phase. Cross-phase tasks are never marked as duplicates, regardless of similarity.
What Happens to Duplicates
When a duplicate is detected:
- The task is marked with status
duplicated - The
duplicate_of_task_idfield points to the original task - The similarity score is recorded
- No agent is created — saving compute resources
- The duplicate task remains in the database for tracking
This prevents wasted work while maintaining visibility into what agents tried to create.
Configuration
Control deduplication behavior in hephaestus_config.yaml:
task_deduplication:
enabled: true # Turn on/off
similarity_threshold: 0.92 # Threshold for duplicates (0-1)
related_threshold: 0.5 # Threshold for "related" tasks
embedding_model: "text-embedding-3-large"
embedding_dimension: 3072
Thresholds matter:
similarity_threshold: 0.92— Tasks above this are duplicatesrelated_threshold: 0.5— Tasks between 0.5-0.92 are "related" (tracked but not blocked)
Higher thresholds = fewer false positives, but may miss some duplicates. Lower thresholds = catch more duplicates, but may mark distinct tasks as duplicates.
The Tradeoff
Semantic deduplication solves the coordination problem in autonomous multi-agent systems. But it introduces a latency cost: every task creation requires an embedding generation (~100-200ms) and similarity comparison against existing tasks.
For most workflows, this tradeoff is worth it. The cost of duplicate work far exceeds the cost of checking for duplicates.
If your workflow has thousands of tasks and performance becomes an issue, you can:
- Disable deduplication for specific phases
- Increase the similarity threshold to reduce false positives
- Migrate to a dedicated vector database (Pinecone, Weaviate) for faster similarity search
When It Doesn't Apply
Deduplication is disabled when:
- No OpenAI API key is configured
- The feature is explicitly disabled in config
- The task doesn't have a
phase_id(it only compares against other tasks without phases)
The Bottom Line
Hephaestus gives agents the freedom to discover and create work independently. Semantic deduplication ensures that freedom doesn't result in redundant effort.
Multiple agents can explore different paths through a problem space, and the system automatically prevents them from duplicating each other's work — all while maintaining the flexibility that makes autonomous agent systems powerful.